# Vuex、Vue-Router、性能优化
# Vuex
# 什么是“状态管理模式”
这个状态自管理应用包含以下几个部分:
- state,驱动应用的数据源;
- view,以声明方式将 state 映射到视图;
- actions,响应在 view 上的用户输入导致的状态变化。
# Vuex 核心思想
Vuex 应用的核心就是 store(仓库)。“store”基本上就是一个容器,它包含着你的应用中大部分的状态 (state)。有些同学可能会问,那我定义一个全局对象,再去上层封装了一些数据存取的接口不也可以么?
Vuex 和单纯的全局对象有以下两点不同:
Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
你不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用。
另外,通过定义和隔离状态管理中的各种概念并强制遵守一定的规则,我们的代码将会变得更结构化且易维护。
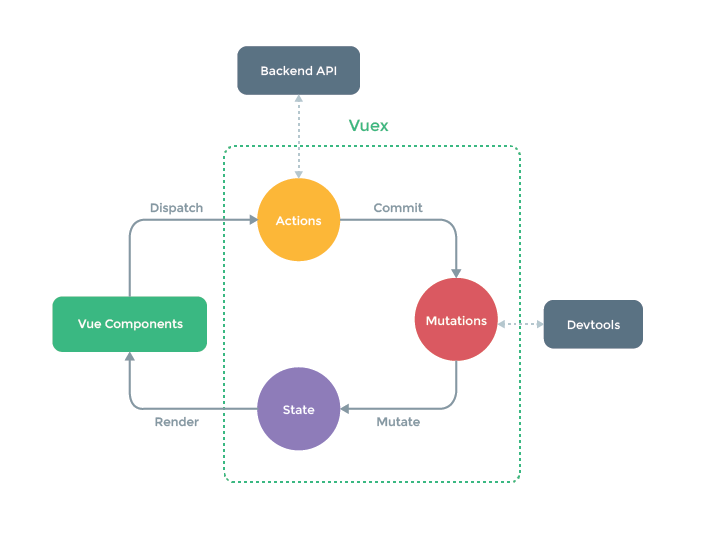
# State
Vuex 使用单一状态树,用一个对象就包含了全部的应用层级状态。至此它便作为一个“唯一数据源”而存在。这也意味着,每个应用将仅仅包含一个 store 实例。
在 Vue 组件中通过计算属性(computed)获得 Vuex 状态,Vuex 通过 store 选项,提供了一种机制将状态从根组件“注入”到每一个子组件中(需调用 Vue.use(Vuex)),子组件能通过 this.$store 访问到。
可以使用 mapState 辅助函数,帮助我们生成计算属性。
# Getter
Vuex 允许我们在 store 中定义“getter”(可以认为是 store 的计算属性)。就像计算属性一样,getter 的返回值会根据它的依赖被缓存起来,且只有当它的依赖值发生了改变才会被重新计算。
- 属性访问:
store.getters.doneTodos - 对象访问:通过让 getter 返回一个函数,来实现给 getter 传参,
store.getters.getTodoById(2)
注意,getter 在通过方法访问时,每次都会去进行调用,而不会缓存结果。
mapGetters 辅助函数仅仅是将 store 中的 getter 映射到局部计算属性
# Mutation
更改 Vuex 的 store 中的状态的唯一方法是提交 mutation。
Vuex 中的 mutation 非常类似于事件:每个 mutation 都有一个字符串的 事件类型 (type) 和 一个 回调函数 (handler)。
# Action
Action 类似于 mutation,不同在于:
- Action 提交的是 mutation,而不是直接变更状态。
- Action 可以包含任意异步操作。
# Module
由于使用单一状态树,应用的所有状态会集中到一个比较大的对象。当应用变得非常复杂时,store 对象就有可能变得相当臃肿。
为了解决以上问题,Vuex 允许我们将 store 分割成模块(module)。
每个模块拥有自己的 state、mutation、action、getter、甚至是嵌套子模块——从上至下进行同样方式的分割。
学习资料:
# Vue Router
例如,在 User 组件的模板添加一个 <router-view>:
const User = {
template: `
<div class="user">
<h2>User {{ $route.params.id }}</h2>
<router-view></router-view>
</div>
`,
};
要在嵌套的出口中渲染组件,需要在 VueRouter 的参数中使用 children 配置:
const router = new VueRouter({
routes: [
{
path: "/user/:id",
component: User,
children: [
{
// 当 /user/:id/profile 匹配成功,
// UserProfile 会被渲染在 User 的 <router-view> 中
path: "profile",
component: UserProfile,
},
{
// 当 /user/:id/posts 匹配成功
// UserPosts 会被渲染在 User 的 <router-view> 中
path: "posts",
component: UserPosts,
},
],
},
],
});
vue-router 有 3 种路由模式:hash、history、abstract,对应的源码如下所示:
switch (mode) {
case "history":
this.history = new HTML5History(this, options.base);
break;
case "hash":
this.history = new HashHistory(this, options.base, this.fallback);
break;
case "abstract":
this.history = new AbstractHistory(this, options.base);
break;
default:
if (process.env.NODE_ENV !== "production") {
assert(false, `invalid mode: ${mode}`);
}
}
其中,3 种路由模式的说明如下:
- hash: 使用 URL hash 值来作路由。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器;
- history: 依赖 HTML5 History API 和服务器配置。具体可以查看 HTML5 History 模式;
- abstract: 支持所有 JavaScript 运行环境,如 Node.js 服务器端。如果发现没有浏览器的 API,路由会自动强制进入这个模式.
# vue-router 中常用路由模式实现原理
# hash 模式的实现原理
早期的前端路由的实现就是基于 location.hash 来实现的。
location.hash 的值就是 URL 中 # 后面的内容。比如下面这个网站,它的 location.hash 的值为 '#search':
https://www.word.com#search
hash 路由模式的实现主要是基于下面几个特性:
- URL 中 hash 值只是客户端的一种状态,也就是说当向服务器端发出请求时,hash 部分不会被发送;
- hash 值的改变,都会在浏览器的访问历史中增加一个记录。因此我们能通过浏览器的回退、前进按钮控制 hash 的切换;
- 可以通过 a 标签,并设置 href 属性,当用户点击这个标签后,URL 的 hash 值会发生改变;或者使用 JavaScript 来对 loaction.hash 进行赋值,改变 URL 的 hash 值;
- 我们可以使用 hashchange 事件来监听 hash 值的变化,从而对页面进行跳转(渲染)。
# history 模式的实现原理
HTML5 提供了 History API 来实现 URL 的变化。
其中做最主要的 API 有以下两个:history.pushState() 和 history.repalceState()。
这两个 API 可以在不进行刷新的情况下,操作浏览器的历史纪录。
唯一不同的是,前者是新增一个历史记录,后者是直接替换当前的历史记录,如下所示:
window.history.pushState(null, null, path);
window.history.replaceState(null, null, path);
history 路由模式的实现主要基于存在下面几个特性:
- pushState 和 repalceState 两个 API 来操作实现 URL 的变化 ;
- 我们可以使用 popstate 事件来监听 url 的变化,从而对页面进行跳转(渲染);
history.pushState()或history.replaceState()不会触发 popstate 事件,这时我们需要手动触发页面跳转(渲染)。
学习资料:深度剖析:前端路由原理
# Proxy 与 Object.defineProperty 优劣对比
Proxy 的优势如下:
- Proxy 可以直接监听对象而非属性;
- Proxy 可以直接监听数组的变化;
- Proxy 有多达 13 种拦截方法,不限于 apply、ownKeys、deleteProperty、has 等等是 Object.defineProperty 不具备的;
- Proxy 返回的是一个新对象,我们可以只操作新的对象达到目的,而 Object.defineProperty 只能遍历对象属性直接修改;
- Proxy 作为新标准将受到浏览器厂商重点持续的性能优化,也就是传说中的新标准的性能红利;
Object.defineProperty 的优势如下:
- 兼容性好,支持 IE9,而 Proxy 的存在浏览器兼容性问题,而且无法用 polyfill 磨平。
# Proxy & Reflect
# 服务端渲染 SSR 的优缺点
# 服务端渲染的优点
- 更好的 SEO
因为 SPA 页面的内容是通过 Ajax 获取,而搜索引擎爬取工具并不会等待 Ajax 异步完成后再抓取页面内容,所以在 SPA 中是抓取不到页面通过 Ajax 获取到的内容;而 SSR 是直接由服务端返回已经渲染好的页面(数据已经包含在页面中),所以搜索引擎爬取工具可以抓取渲染好的页面;
- 更快的内容到达时间(首屏加载更快)
SPA 会等待所有 Vue 编译后的 js 文件都下载完成后,才开始进行页面的渲染,文件下载等需要一定的时间等,所以首屏渲染需要一定的时间;SSR 直接由服务端渲染好页面直接返回显示,无需等待下载 js 文件及再去渲染等,所以 SSR 有更快的内容到达时间;
# 服务端渲染的缺点
- 更多的开发条件限制
例如服务端渲染只支持 beforCreate 和 created 两个钩子函数,这会导致一些外部扩展库需要特殊处理,才能在服务端渲染应用程序中运行;并且与可以部署在任何静态文件服务器上的完全静态单页面应用程序 SPA 不同,服务端渲染应用程序,需要处于 Node.js server 运行环境;
- 更多的服务器负载
在 Node.js 中渲染完整的应用程序,显然会比仅仅提供静态文件的 server 更加大量占用 CPU 资源 (CPU-intensive - CPU 密集),因此如果你预料在高流量环境 ( high traffic ) 下使用,请准备相应的服务器负载,并明智地采用缓存策略。
# Vue 性能优化
学习资料:
# Vue 前端工程化开发技巧
# Vue 源码解析
- Vue.js 技术揭秘
- Vue 源码解析 - 小马哥老师 视频
- 剖析 Vue.js 内部运行机制
- Vue 逐行级别的源码分析 - HcySunYang 大佬
- Vuex 源码解析
# Vue 学习资料
- Vue 官方文档 API、Vuex
- 从源码解读 Vue 生命周期,让面试官对你刮目相看
- 12道vue高频原理面试题,你能答出几道
- 20+Vue 面试题整理 🔥(持续更新)
- 30 道 Vue 面试题,内含详细讲解(涵盖入门到精通,自测 Vue 掌握程度)
- Vue 开发必须知道的 36 个技巧【近 1W 字】
- Vue 组件间通信六种方式(完整版)
- 深入实践 ES6 Proxy & Reflect
- Vue.js 技术揭秘